JavaScriptのreduceについて

mapに引き続きreduceについてです。
mapはある配列から新たな配列を作成するための関数でした。
reduceは、ある配列から結果を集めるために使用します。
例えば、以下のような商品データがあるとします。
const products = [
{code: '001', price: 100},
{code: '003', price: 200},
{code: '002', price: 300},
{code: '001', price: 400},
];これをcodeごとにいくつあるかを集計したいとします。つまり以下のような結果を得たいとします。
{
001: 2,
002: 1,
003: 1
}
reduceは、配列の各要素に対して関数を適用し、その結果を積算器に加算して計算します。
言葉だと難しいですが、図で示すと以下のような感じです。
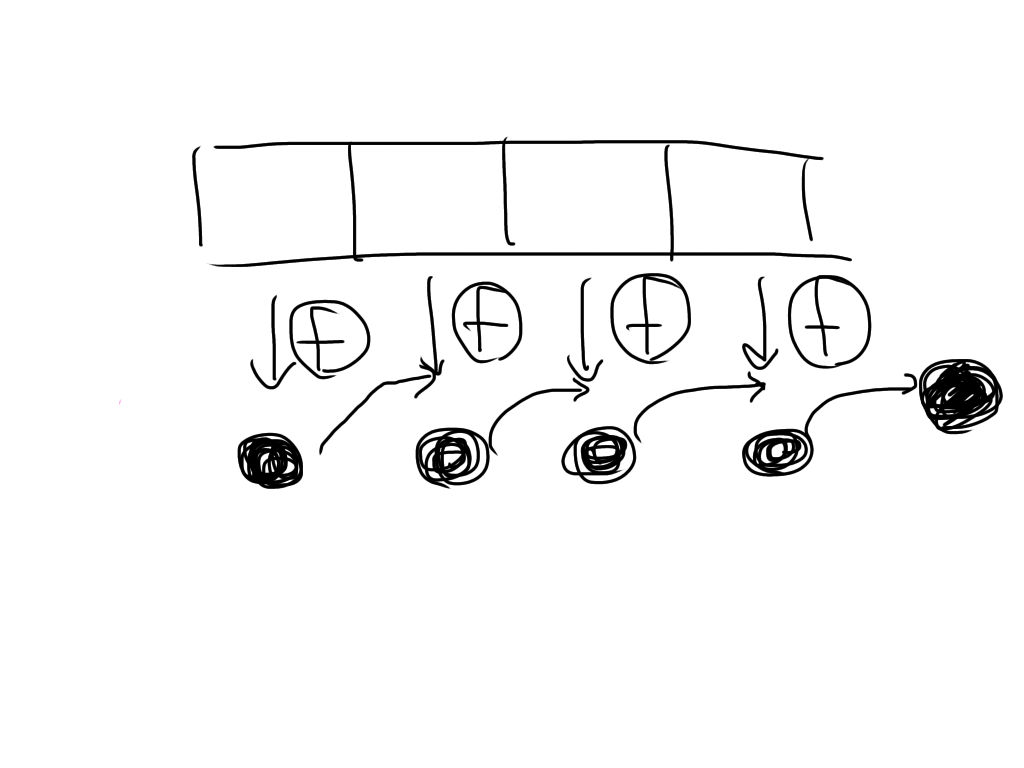
配列の始めの要素を関数fで処理します。
その結果が黒丸です。この黒丸を次の配列の要素の処理の時に渡し、二つ目の処理の結果を黒丸に加えます。
これを最後の配列の要素まで繰り返します。
先ほどの例の場合は、以下のようなコードになります。
const products = [
{code: '001', price: 100},
{code: '003', price: 200},
{code: '002', price: 300},
{code: '001', price: 400},
];
const result = products.reduce((summary, product) => {
const code = product['code'];
summary = summary === undefined ? 1 : summary + 1;
return summary;
}, {});
console.log(result);reduceの第一引数に渡している関数が、各配列の要素に対して実行する関数です。
第二引数が積算器の初期値です。上の例ですと{}(空のオブジェクト)です。
はじめの配列の要素{code: '001’, price: 100}に対して関数を適用した結果、積算器(summaryの値)は{001:1}となります。
summaryの推移は以下です。難しく見えますが配列の要素に関数を適用した結果を、summaryに加えているだけです。
//初期値
{}
//一つ目の要素の処理後
{
001: 1
}
//二つ目の要素の処理後
{
001: 1,
003: 1
}
//三つ目の要素の処理後
{
001: 1,
002: 1,
003: 1
}
//最後の要素の処理後
{
001: 2,
002: 1,
003: 1
}補足
今回の例をmapを使ってさらに柔軟性を持たせてみます。
const getCode = product => product.code
const summarizeCode = (summary, code) => {
summary = summary === undefined ? 1 : summary + 1;
return summary;
}
const products = [
{code: '001', price: 100},
{code: '003', price: 200},
{code: '002', price: 300},
{code: '001', price: 400},
];
// 今回の処理はこれ
const result = products.map(getCode).reduce(summarizeCode, {})
console.log(result);productからcodeを取得する処理としてgetCodeを、codeを集計する処理をsummaryCodeという関数に切り出しました。
あとは、mapとreduceの引数にこれらの関数を渡すだけです。
このようにすることで、products.map(getCode).reduce(summarizeCode, {}) の部分は、各関数の実装をみなくても、これだけみてなんとなく何をしているか分かると思います。
このように可読性が上がります。
さらに、getCodeやsummarizeCodeという関数は、純粋な関数(※1)なため再利用も簡単です。
※1 同じ入力に対して常に同じ結果を返して、関数の外には影響は与えない
関数の引数に関数を渡せるということが、可読性や再利用性の向上の助けになることがなんとなくイメージできれば思います。